
This blog series introduces the Azure Kubernetes Service (AKS). It introduces important terms in this context and gives an overview of where AKS can support a container-based application and offers advantages over “pure” Kubernetes. The whole is divided into the areas:
- Cluster Management
- Availability
- Security
- Scaling
- Service Integration and
- Monitoring.
Finally, a few tips and best practices follow.
Overview on the series:
- AKS Part 1 – general terms and availability options
- AKS Part 2 – network, storage and tools
- AKS Part 3 – security topics
- AKS Part 4 – scaling and monitoring
- AKS Part 5 – advanced integration with other services
- AKS Part 6 – cluster architecture, hints & tricks and hands-on
In this first part, I’ll cover general terms and availability options.
What is AKS?
The open source project Kubernetes (K8S) has long been the talk of the town and has established itself as THE container orchestration tool. It already has many practical features, mainly for the context of a microservice-based multi-container application. For example, there are the possibilities of updates without downtime, scalability, service discovery or self-healing techniques.
However, installing and operating a Kubernetes cluster yourself means a lot of effort. This is where Azure Kubernetes Service (AKS) comes in. This is a managed Kubernetes service in the Azure Cloud. AKS also uses Kubernetes and targets container applications, but also provides support in many areas such as node management, security, scaling and monitoring. This greatly simplifies the installation and operation of a Kubernetes cluster.
AKS Facts & Terms
Cluster Management
The virtual machines for controlling the cluster – the master nodes – are completely managed by Microsoft and are free of charge. You only have to pay for the computing power of the worker nodes, their memory requirements and network resources.
Linux and Windows machines are available for the worker nodes on which the applications run.
The Figure down below illustrates the division of labour. The components are already known from Kubernetes. The master nodes consist of the API server, the etcd database, the scheduler and the controller manager. The API server receives commands and checks them. The state of the cluster is stored in the etcd database. The scheduler controls which pods (with the containers) are placed on which nodes. The Controller Manager manages Replica Set Controllers and Deployment Controllers. The left part is completely managed by Azure, including scaling or, for example, patching the virtual machines.
On the virtual machines of the worker nodes, there is the kubelet agent for communication with the API server and pod creation, the kube proxy for network tasks and a container runtime. AKS also supports on these components; they do not have to be installed manually on the nodes.
Pods, replica sets, deployments, nodes and node pools are of course also relevant for AKS.[1]
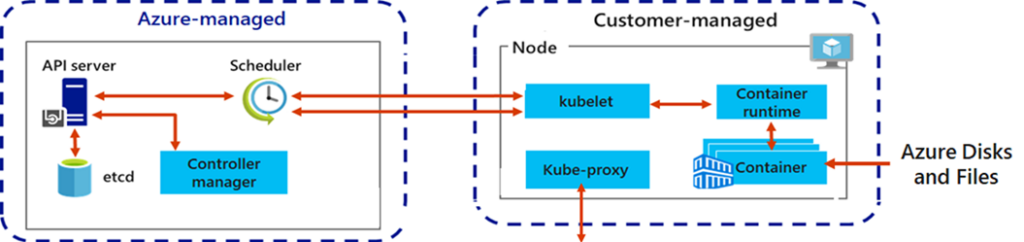
Fig. 1: AKS components©Microsoft
Worker Nodes
A node pool describes a set of identical virtual machines, also called worker nodes, on which the applications are run. In terms of Azure resources, this can be individual VMs or virtual machine scale sets. Furthermore, it is possible to use virtual nodes, more on this in the topic of scaling. Different types of virtual machines can be selected for the pools, for example CPU-optimised series or those with GPUs. For increased security and compliance requirements, the Compute Isolation model can also be selected, where physical servers in the Azure Data Center are not shared with other customers.
High Availability
The Node Auto-Repair function helps to identify unhealthy nodes and restart them if necessary.[2]
To ensure higher availability of the worker nodes, they can be distributed by pool to Availability Zones, which means they are distributed to several data centres in a region.
For very critical workloads, a chargeable SLA option can also be booked, which increases availability to 99.95% through additional resources at the master nodes when using Availability Zones. The SLA is then also financially secured if the promise on the part of Azure is not kept.[3]
For disaster recovery requirements, e.g. multi-region clusters can be used. The AKS clusters are set up in different regions for fail-safety and the global request distribution is achieved with the help of an Azure Traffic Manager, as shown in the picture below.
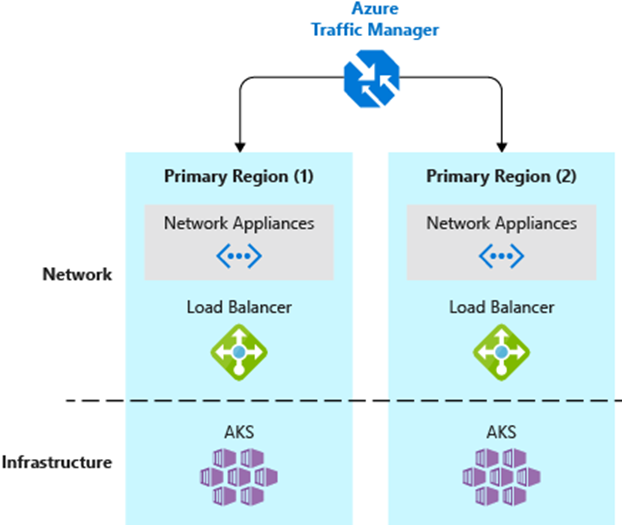
Fig. 2: Multi-Region Cluster ©Microsoft
Container images can also be replicated globally if the corresponding SKU is used in the Azure Container Registry. This reduces image pull latency, increases availability and saves network transfer costs.[4]
(Next part coming soon)
[1] https://docs.microsoft.com/en-us/azure/aks/concepts-clusters-workloads
[2] https://docs.microsoft.com/en-us/azure/aks/node-auto-repair
[3] https://docs.microsoft.com/en-us/azure/aks/uptime-sla
[4] https://docs.microsoft.com/en-us/azure/aks/operator-best-practices-multi-region