
To make Terraform Code more dynamic, shorter, and more reusable, there are several options. We will look at them in the following section and try not to lose the red thread despite the links between them.
Our focus is on:
- if options
- Count
- for_each
- for
- dynamic blocks
if options
A typical if-then-else construct, as known from many programming languages, does not exist in Terraform. Only in the for construct discussed later can the keyword “if” appear. However, conditions can be formulated using the ternary syntax:
Condition ? Return for true : Return for false
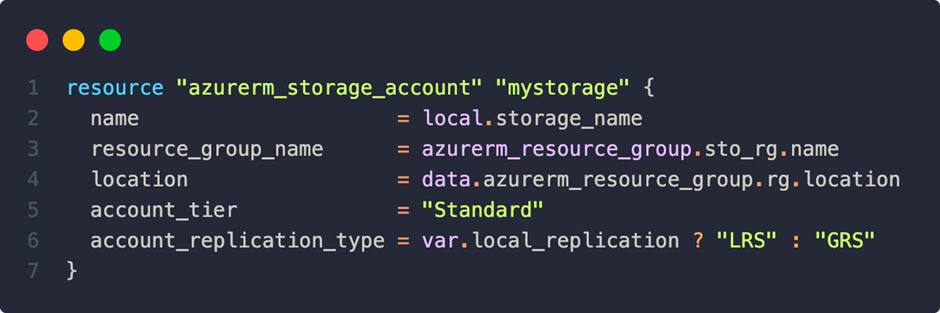
In this example, the variable local_replication is a Boolean, but functions and expressions could also be used at this point.
Count
Count, like for_each, is a Terraform meta argument. These can be used as auxiliary constructs in resource blocks or modules. The name says it all: it’s about a number, for example, instead of one, three storage accounts are to be deployed, which are configured in the same way – or possibly none at all. Terraform, when using Count, builds an internal array and works with its indexes. These values canalso be used in the resource via ${count.index}.
Here’s what would work:
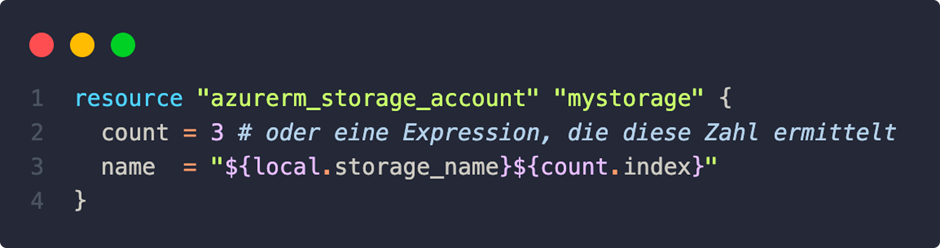
At the end of each name, we would have 0, 1, and 2.
Warning!
However, our own practice and the Hashicorp documentation advise against this type of use. A big problem can arise, for example, if the value for Count is taken from a list, for example with the names of the accounts:

Assuming the names were still globally unique, Terraform would deploy. However, if an element is then removed from the variable list, e.g. “account2“, the index referencing causes a probably undesirable effect (delete the second one and leave the third one):
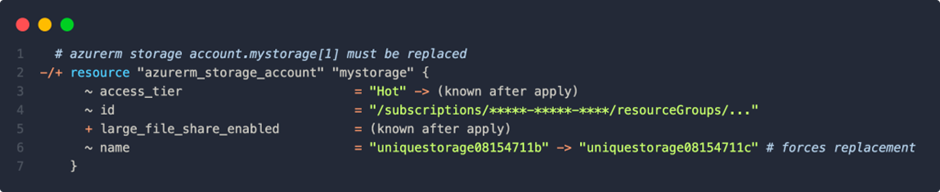
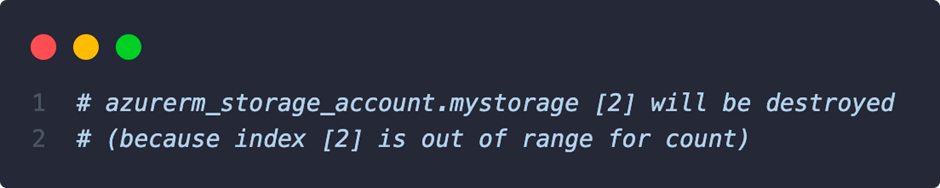
Terraform detects a name change for the 2nd index and the third no longer exists. “account3” is therefore recreated as a replacement for the second one – the data would be gone.
Count is more recommended as a switch as to whether a resource should be created at all. Together with the ternary syntax, for example, the following could be defined:

If the condition is evaluated as true, the resource is deployed – otherwise not[1].
for each – usually the better way
Iterating over collections and objects is safer and more convenient over the for_each argument. Terraform also works internally with an object at this point, so that there are no problems with index referencing. A generated each-object can be accessed per iteration, which returns each.key aswell as each.value. In the case of arrays, these two values are the same.
To illustrate, let’s create containers within the storage account:

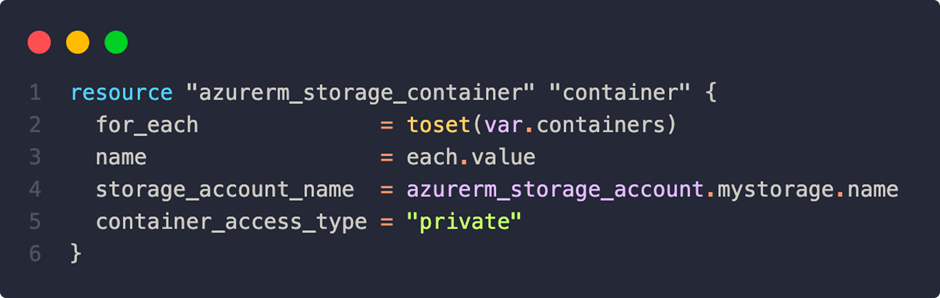
Lists cannot be processed directly in the for_each, the toset() function provides a remedy here. It is also possible to pass for_each an expression that may result in an empty object or array – then no resources would be created at this point.

Count and for_each cannot be used at the same time. In addition, in both cases, the values passed to the arguments must be available in the plan step. A reference to resources to be deployed first does not work.
for
For is itself an expression and not a meta-argument as in the other examples. With for, an object or its values can be iteratively converted to another object with conditions and other expressions. Similarities with the classic for loop from programming are present but should not be confused with the concept. Depending on whether the for-statement is enclosed with {} or [], an object or tuple is returned. [2]
The basic syntax is:
for variablename(s) in collection/object : result object
for is very flexible and can take different types such as arrays or objects as input and also create new ones.
- if two variable names are specified, they refer to the key/value pair of an object, or the first represents the index of an array
- the result object can become a new collection if only one expression follows the colon
- If this is followed by an =>, a new key-value result object is also created.
- The result object can be filteredusing the if keyword.
for is especially helpful in combination with for_each to get filtering and adjustments in the input for the meta argument:
As an example of our storage, the following is conceivable:


Result:

The first for construct creates an object, and the second creates a collection. Both adjust the container name and filter out an item that is “too short” from the input list. The index variable is optional for arrays as input.
A compilation of the option presented so far in this section with practical examples can also be found at[3]
Dynamic blocks
Many Terraform resource types use defined objects in addition to key-value pairs for configuration within their blocks. For example, the creation of subnets in virtual networks or, in keeping with our example, the definition of network rules is governed by this approach. There can often be several of these objects. In order not to repeat code unnecessarily, Terraform supports this with dynamic blocks.
The basic structure is as follows:

The value after the dynamic keyword corresponds to the name of the configuration object. If no individual iterator is specified, it can be used to refer to the current item in the collection (for_each) to be iterated. The content of theconfiguration object is then defined in the content block.
With regard to our storage account and its network rules, this can look like this:

Other common examples of using dynamic are virtual network subnets or network security groups. Dynamic blocks are also supported in data, provider and provisioner blocks.[4]
Data Queries
To complete the picture of options for dynamization, the principle of data queries should be explained at this point.
In practice, cloud environments are rarely provisioned or managed in one piece. For example, there are central platform areas with network resources and firewalls as well as various use case applications that later integrate into the network. However, for the creation of an application infrastructure, this means that certain resources are already existing. To access these attributes for the configuration of the application, the Terraform feature data-Blocks can be used.
The blocks follow a similar structure to these for resources and define API requests to the desired existing services. The general structure is as follows:

Referencing within the configuration is done via the data keyword. Which specific information within the data block is necessary to find the corresponding resource can be found in their respective sections of the documentation.
A simple example of our defined resource group would be:

The query then returns an object with information about the resource, the attributes of which can be used elsewhere:
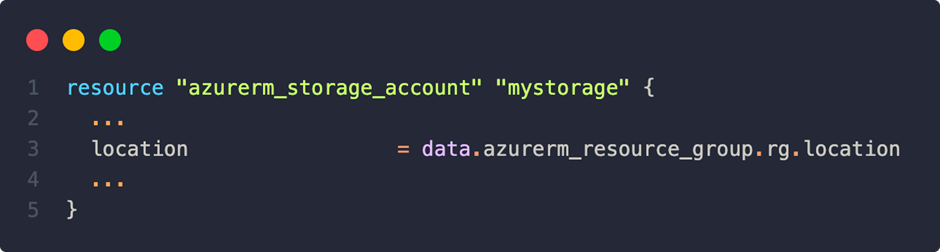
In this example, the region would not be defined in the module itself but would be read by the resource group. To put it simply, data retrieval within the configuration is always required if the resource already exists outside the module used. Frequently, IP addresses for firewall settings or complete resource IDs are also retrieved in this way. For example, there is usually a central Log Analytics workspace for data collection, whose ID is then referenced in this way in a resource’s diagnostic configurations.
In the next part we will look at provider configurations and how to deal with remote backends.
[1] https://developer.hashicorp.com/terraform/language/meta-arguments/count
[2] https://developer.hashicorp.com/terraform/language/expressions/for
[3] https://blog.gruntwork.io/terraform-tips-tricks-loops-if-statements-and-gotchas-f739bbae55f9#:~:text=Terraform%20offers%20several%20different%20looping,within%20a%20resource%2C%20and%20modules
[4] https://developer.hashicorp.com/terraform/language/expressions/dynamic-blocks