
With this post, we continue the series on managing Azure infrastructure with Terraform, in detail now the implementation within deployment pipelines. After covering the basics you need to know for an Azure DevOps setup in the last blog, we here focus on general pipeline implementation considerations and a first working simple pipeline example.
Step by step – building the pipeline
This section will now deal with the concrete steps of the pipeline. This is written with code in YAML format and, as usual, is itself in the repository. All it takes is a small link in the pipeline section of DevOps to create it. For an overview, it also remains a file, pipeline templates and multi-repository approaches are not examined in more detail. We will use a total of three jobs with some tasks.
Tips on the general procedure
For the development of a pipeline, a few general tips are given at this point, which are also relevant for Terraform deployments and have established themselves as best practice approaches.
The basic motto is: Everything step by step. It is always a good idea to start small with a minimal set of tasks and Terraform configurations in order to have a “green” pipeline as a basis. Many and especially technically more complicated resources such as a VPN gateway can cost a lot of unnecessary time during pipeline runs if there are actually other errors hidden in the YAML. Therefore, it is best to start with only one resource group or storage account, for example. If it is ensured that file paths for repositories are correct, the access of the Service Connection works and the statefile is correctly integrated, the pipeline can be developed more relaxed. A simple script task like echo $(Build.SourcesDirectory) can be very helpful to see the correct folder structure or variable values, which is also where Terraform Deployment can be lacking. It is also legitimate to validate and test the pure Terraform code locally on your own machine before it enters the pipeline, a remote backend can also be set up locally. A pipeline run always takes some time. For steps like terraform fmt, it’s a good idea to place them inside pre-commit hooks[1] and thus force more readable code. It is also good DevOps practice to secure pull requests with branch policies and an additional pipeline. Here, for example, a terraform validate and plan makes sense, as described in detail here[2]. If you are using the free public agent as described in the series, you can find the number of free minutes still available in the month under Parallel jobs in the Organization settings.
Classic pipelines via the DevOps editor are not advisable, at least for new projects. Microsoft’s development focus is on YAML.
Powershell Tasks or Terraform Tasks?
To put it simply, the same Terraform steps must be built into the pipeline as known from local development. At the very least, we find terraform init and apply as the typical steps for deploying the infrastructure.
Here the question arises as to how much individual scripting can be found in the pipeline. More precisely, whether predefined tasks, integrated in Azure DevOps or from the marketplace or direct commands, e.g. via PowerShell, are used. In practice, there are both. Own scripting has the advantage that you can act (almost) independently of third parties. Known commands can possibly be adopted directly and the transition becomes easier in the event of migrations of the pipelines, e.g. to GitHub Actions. Marketplace tasks are still a kind of black box despite the public GitHub repository and can cause problems if changes have been made by the provider. However, there is definitely maturity in many of these tasks and the readability of the pipeline is usually increased, as some functions are encapsulated and the task becomes leaner and more readable. The pipeline for this post uses the Marketplace Azure Pipelines Terraform Tasks[3] from Jason Johnson, formerly published by Charles Zipp specific to the Terraform CLI. The tasks must be installed as an extension in the DevOps organization.
Another option of tasks for the DevOps pipeline would be TerraformTaskV4@4.
Pipeline Security
At this point, a few thoughts on security aspects, although this alone would certainly justify a complete article. There are several options regarding the handling of secrets, but of course they have no place in the repository.
A justifiable approach is the possibilities within Azure DevOps, in the library area of the pipelines. Information worthy of protection can be created as variables in variable groups and marked as secret, it can no longer be seen in plain text after saving. At the same time, there are secure files for entire files, for example with SSH keys or certificates, which also represent a special protected resource in DevOps. An Azure KeyVault connection works in the background to decrypt the values. The data can then be consumed within the pipeline tasks. With these options, however, the secrets cannot be shared beyond the scope of a DevOps project. If you need this and/or still need the extended security of storing the data in a KeyVault, you can map the DevOps variable groups directly to this service. In addition to obvious variable values such as database or VM passwords, storage keys or tokens, information such as the IDs of Azure Subscriptions, Tenants or App Registrations should also be treated as secrets in the context of IaC pipeline.
With regard to the service principals used by Azure DevOps for the pipelines, the recommendation here is also not to distribute the RBAC rights according to least privilege too generously. Using the Service Connections wizard, the automatic principal creation is convenient and still legitimate for dev or demo purposes. However, it also gives contributor rights to the scope, which is quite extensive in the case of a subscription. However, this can be limited to at least one resource group in the wizard. In addition, the Entra ID rights required to create a connection alone can be too high for the pipeline developer at this point. It is therefore more practical to use several existing service principals for the connections, which only get the necessary rights on a smaller scope in the sense of a separation of powers. For example, only to the specific deployment area or with the restriction to read rights for Key Vault access. If you need it even more granular, RBAC custom roles for the principal are a good option.
Pipeline Jobs and Tasks for Terraform
In this section, we’ll take a closer look at the different phases and tasks of an Azure DevOps Pipeline for Terraform.
In a very simple setup, our pipeline only needs tasks for terraform init for preparation and terraform apply for the actual deployment if we use hosted Ubuntu agents and don’t need different stages etc.
For instance:
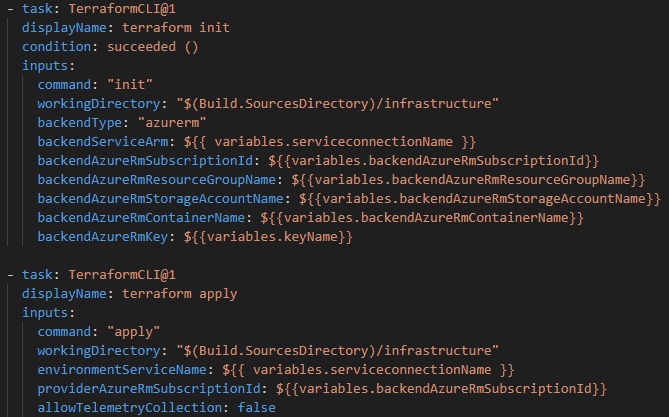
But we are going more in the direction of common practice here. The basic pipeline is expanded with three jobs and the resulting tasks, a security scanner, a separate plan step and an approval gate. Based on the jobs, there is one for preparation, gate and deployment.
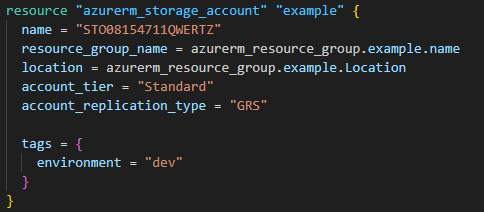
The Terraform configuration is not complex, it just creates a resource group and a storage account. This deliberately has non-optimal security properties for demonstration. There are a few variables to illustrate the input options.
If you work module-based, this works in the same way as in the already known way with an orchestration file for the module calls and the reference options, e.g. via https, ssh or from the file system.
The sample storage resource:
In the next blog we will continue with job definitions in detail.
[1] https://pre-commit.com/
[2] https://thomasthornton.cloud/2020/07/29/validating-terraform-code-during-a-pull-request-in-azure-devops/
[3] https://marketplace.visualstudio.com/items?itemName=JasonBJohnson.azure-pipelines-tasks-terraform