
In the last post of the series, we checked remote modules in detail and when it makes sense at all to work with modules. In this part it’s about the idea of cloud agnostic modules and some of the best practices for working with modules in general.
The Myth of Cloud Agnostic Modules
For a long time, there has been a desire in projects to act as flexibly as possible and independently of a specific hyperscaler. This is also reflected in the IaC area. HashiCorp basically refers to Terraform as a multi-cloud solution.[1] But can it really be said that a multi-cloud strategy can be easily implemented with Terraform?
The answer is probably either the german “jein” or “it depends”. From a purely technical point of view, this can be implemented with HCL. With the help of modules, parameters, and language features such as count, the provider-specific properties could be abstracted, for example with the Facade design pattern. But this work has to be done, Terraform does not have an automatic translation to deploy either a storage account or an S3 bucket, for example. HCL resource types are different for each provider. Even if the properties of a resource are more or less the same, different modules should be defined for the respective providers. Another orchestration module would also be advisable, because the distinction within a service module can quickly become far too complicated due to the differences between the cloud providers. The variable definition doesn’t get any easier at this point.
Whether the effort is worth it can perhaps be answered with the question of why the path to the multi-cloud approach was taken: Because certain services are available at all or with a better set of features from a provider? Maybe because they are cheaper or because a company acquisition has taken place? Then the “desire to change” between providers will probably be quite low.
Nevertheless, it is advisable to pursue a uniform IaC strategy. Using Terraform for AWS and for example Bicep on Azure is likely to cause confusion in the end. A common approach unifies development and DevOps processes, even if different teams develop different modules for their respective provider areas. If the extended tool suite from HashiCorp is used, even more unity can be achieved, for example in security or logging[2]. But here are some additional costs to be considered.
Best Practices Module
Last but not least, here are some general best practice tips from project experiences that have arisen over time:
First develop locally, then bring remotely
During initial development, it is advisable to only bring the module remotely when it is a module that can run on its own. This speeds up the development process enormously, as changes in local modules are immediately available.
Set Minimum Provider Version
With the help of the >= operator, we can set the minimum required provider version in our submodule. If new resources are only available from a certain version, this note helps us to specify the correct provider version in the root module. Without this configuration, you often recognize this problem first during deployment, which can cost a lot of time.
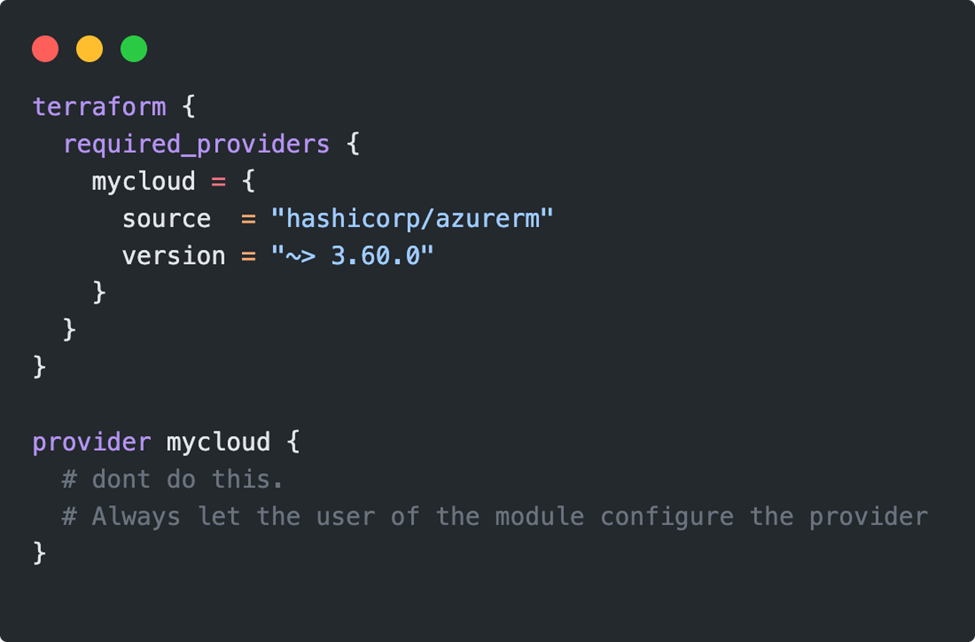
Do not configure providers in submodules
Specifying the ‘required_providers’ block is mandatory, but configuring it using the provider block should not take place in the submodule. The user of the module should decide how he wants to configure the provider. In most cases, this is automatically inherited by the root module.
Using Semantic Versioning for Modules
For versioning, an existing concept can be used without any problems. It is a good idea to use the Semantic Version Model. This consists of 3 blocks and follows the pattern xx.xx.xx. The first block represents the major version, the second describes the minor version, and the third block represents the patch version. More information about the SemVersion can be found on the official website[3].
Refactoring
Caution is advised when refactoring the code. If an already created resource is moved to a module, the internal name of the resource for Terraform is no longer found in the configuration. So as a result, Terraform plans to destroy the resource and redeploy it:
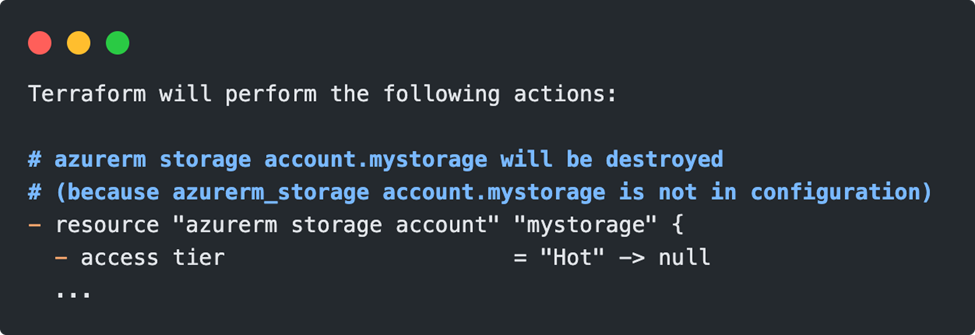
If this is unacceptable, the problem can be fixed with the terraform state mv command.
Modules in iterations
As known from classical programming, code outsourced to modules is often executed in a loop or iteration. Of course, this also applies to Terraform modules, which can also be called in a more dynamic version. Both count and for_each known from the last posts are supported. Here, too, however, as described in the last blogs, the latter is recommended due to the same challenge with index values[4].
To call our webapp module with for_each, not much needs to be changed. We add a variable “webapp_names_list” of type set(string) at the orchestration level, the module itself does not need any customization. The tfvars file is also extended accordingly:
webapp_names_list = [ “myfancywebapp08154711”, “myfancywebapp08154711-2nd”]
The customized module call uses the value keyword and looks like this:

According to our definition, two webapps are now created on two App Service Plans. Further adapting the module code, for example to create both apps on one plan, could be a useful extension. However, this should also make it clear that the definition of Terraform modules is not without complexity.
for_each can only work with map or set objects, direct use of the type list(string) does not work. The toset() function, which converts and removes duplicates, can help at this point.
There are two pitfalls lurking in our customization, as Terraform now works with arrays in the background:
- the original webapp is to be rebuilt
- the output reference no longer works as before
The definition of the webapp resources in the statefile is now also changed to an array, instead of “module”: “module.webapp” there is an index referencing []:
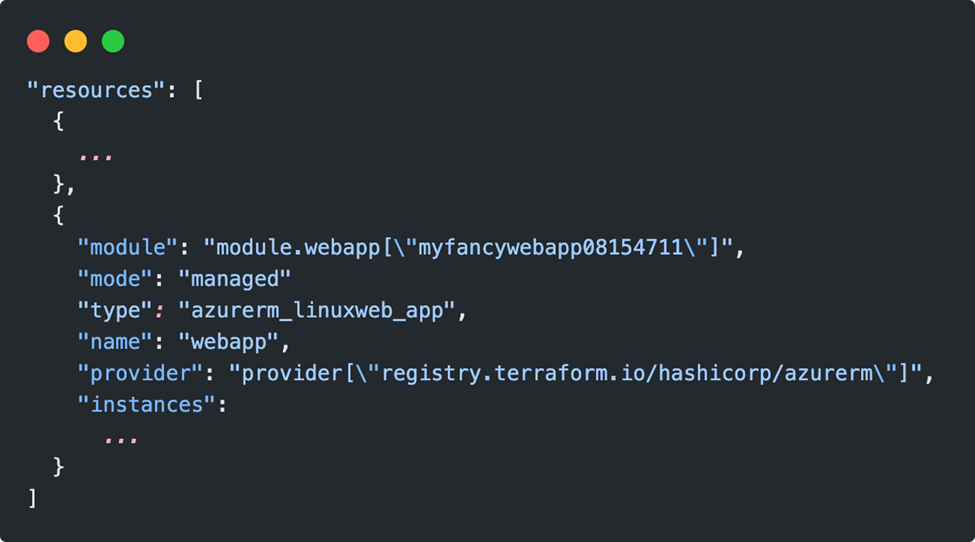
As a result, Terraform wants to clear the “old” resource and create a new one.
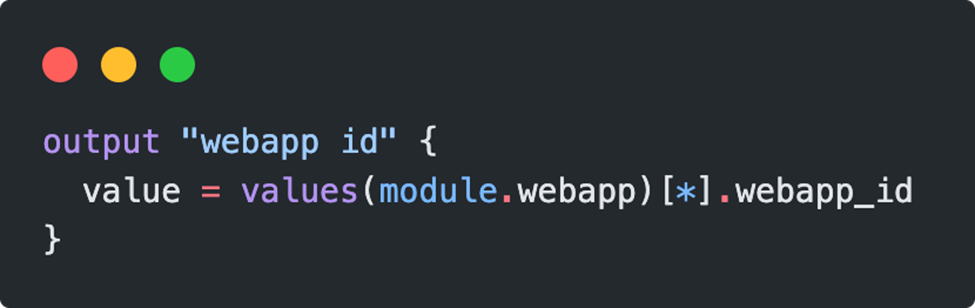
Our output definition also needs to be adjusted, because the return object of the deployment also has a different structure:
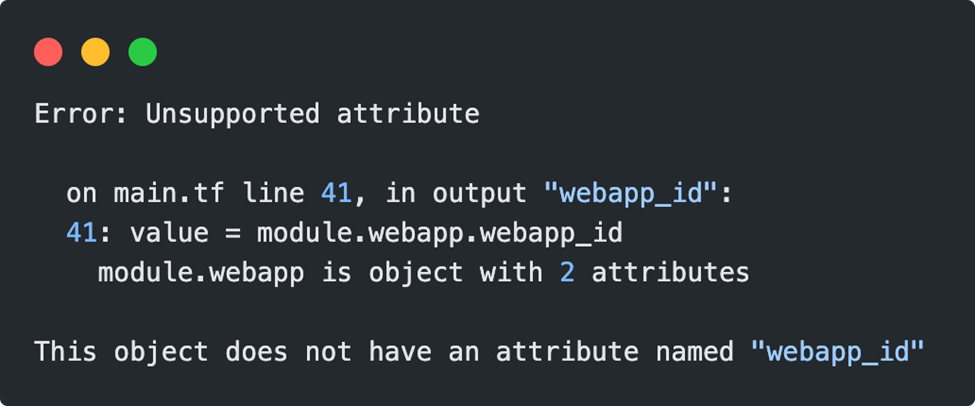
With the help of the values() function, which can return a list of values in a map object, as well as a splat expression[5] for all existing elements [*], the ID of the webapp can be retrieved, for example:
Conclusion & Outlook of modules
We have taken a detailed look at the modularization of Terraform Code. We have taken a close look at how modules are structured and how their call works exactly. We looked into local and remote definition as well as when it makes sense to use them in general and what the best practices are. Building on this, we’ll go one step further in the next parts of the Terraform post series and look towards automating Terraform deployments. Keyword: (Azure) DevOps Pipelines.
[1] https://www.hashicorp.com/products/terraform/multi-cloud-compliance-and-management
[2] https://www.hashicorp.com/products/terraform/multi-cloud-compliance-and-management
[3] https://semver.org/lang/de/
[4] https://developer.hashicorp.com/terraform/tutorials/configuration-language/for-each#add-for_each-to-the-vpc
[5] https://developer.hashicorp.com/terraform/language/expressions/splat